 | Products |
| Home » Products » ElevateDB for Java, C/C++, or Other Database Developers |
Navigational and SQL Access Methods
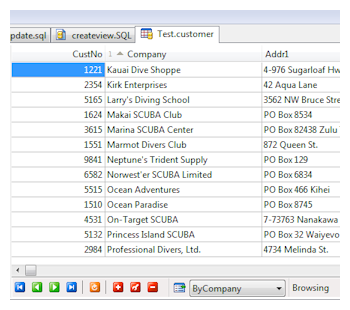 ElevateDB supports both navigational and SQL access methods. This means that you can:
ElevateDB supports both navigational and SQL access methods. This means that you can:
SQL Support
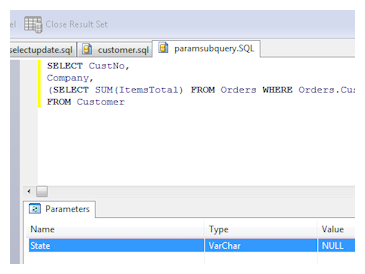 ElevateDB supports a large subset of the SQL-2003 SQL language for DML (data-manipulation) and DDL (data-definition) statements, and includes the following features:
ElevateDB supports a large subset of the SQL-2003 SQL language for DML (data-manipulation) and DDL (data-definition) statements, and includes the following features:
SQL/PSM Support
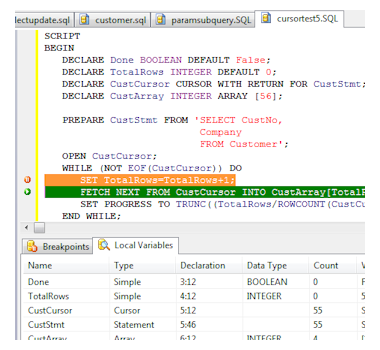 ElevateDB supports a variant of the SQL-2003 SQL/PSM language for scripts, jobs, stored procedures, functions, and triggers that is geared towards dynamic SQL, and includes the following features:
ElevateDB supports a variant of the SQL-2003 SQL/PSM language for scripts, jobs, stored procedures, functions, and triggers that is geared towards dynamic SQL, and includes the following features:
Replication
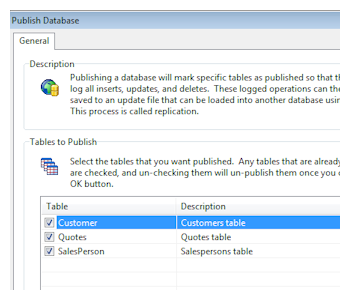 ElevateDB includes an extremely flexible replication system that consists of the following features:
ElevateDB includes an extremely flexible replication system that consists of the following features:
Transparent Local and Client-Server Access
 Changing between local and client-server access requires a simple modification to the TYPE connection string attribute in the ODBC connection string. ElevateDB C/S access is automatically optimized for most LAN/WAN implementations, with features like:
Changing between local and client-server access requires a simple modification to the TYPE connection string attribute in the ODBC connection string. ElevateDB C/S access is automatically optimized for most LAN/WAN implementations, with features like:
ElevateDB supports both navigational and SQL access methods. This means that you can:- Directly Access Tables and Views
You can directly access and update a table or view using by using a dynamic, bi-directional cursor on a simple SELECT * FROM <Table> type of SQL query. The dynamic cursor can be updated in-place using the native ODBC functions for inserting, updating, or deleting rows from a cursor. - Execute SQL Statements and Stored Procedures
You can access and update tables using the native ODBC SQL execution functions. Both sensitive and insensitive result sets can be returned from any SELECT statement, and you can access and update any result set using the native ODBC functions for navigating and updating cursors.
SQL Support
ElevateDB supports a large subset of the SQL-2003 SQL language for DML (data-manipulation) and DDL (data-definition) statements, and includes the following features:- Catalog and Information Schema Support
ElevateDB includes complete catalog support, including querying the Information schema for database objects and querying the Configuration database for system-wide objects. - Complete User Security
Roles and users can be defined, and privileges assigned to any database or configuration object. - Constraints
Standard primary key, foreign key, unique and check constraints support for tables. - Standard Data Types
All standard data types are supported, including CHAR, VARCHAR, BOOLEAN, SMALLINT, INTEGER, FLOAT, DECIMAL, NUMERIC, CLOB, BLOB, DATE, TIME, and TIMESTAMP. - Generated and Computed Columns
Generated columns are expression columns that are stored in each row and updated automatically when the row is updated. Computed columns are expression columns that are virtual and are evaluated any time any dependent columns are updated. Both can contain references to any system functions, while generated columns can also referenced user-defined functions that can, in turn, execute SQL statements (see SQL/PSM support below). Also, generated and computed columns can be indexed, meaning that they can be used to index columns that are not normally capable of being indexed, such as CLOB and BLOB columns. - CLOB/BLOB Columns
CLOB (large character object) and BLOB (large binary object) columns can be defined that are able to store up to 2GB of data per row. CLOB columns can be used anywhere that a normal VARCHAR column would be used. - Per-Column Collations
Collations can be assigned to any CHAR, VARCHAR, or CLOB column, and can be customized with flags for case-insensitivity, accent-insensitivity, Kana-insensitivity, and width-insensitivity. Indexed columns can override a base columns collation, and column references in any DML SQL statement can be forced to use a specific collation for comparison operators. - Date/Time Interval Support
Complete date/time interval support is included in ElevateDB, allowing you to easily add and subtract dates, times, and timestamps and cast the results to and from various representations of intervals. The standard Year-Month and Day-Time interval types are supported. - Sensitive Result Sets with Sub-Queries
SELECT statements that contain sub-queries (correlated or un-correlated) in the SELECT expression list can return sensitive (updateable) result sets in ElevateDB. This means that you can perform lookups into other tables in the SELECT list and still return a result set that can be directly modified. - Views
Views can be defined using any valid SQL SELECT statement, and can return sensitive (updateable) result sets. Views can also be defined as constrained in order to disallow the insertion of any rows that violate the WHERE clause of the SELECT statement. If any of the base table columns referenced in a view are altered so that their data types have changed, then the view is automatically adjusted to reflect these alterations. - Derived Tables
ElevateDB allows you to specify derived tables in SQL DML statements. A derived table is simply another query that is specified in the FROM clause, given a name, and treated like a table as far as the outer SQL statement is concerned. ElevateDB can also return sensitive result sets from derived tables, and derived tables can be nested as deep as required. - Text Indexing
CHAR, VARCHAR, and CLOB columns can be text-indexed, allowing for very fast indexed word searches that can use wildcards and can be combined with AND and OR operations. Indexed text can be filtered using plug-in text filter modules (DLLs), allowing text to be extracted from document types such as HTML, XML, and RTF prior to indexing, and specific columns can be used to indicate the type of text being filtered. The word generation can also be customized using plug-in word generator modules (DLLs), allowing one to control how words are fed to the text indexing. - Execution Plans and Hints
ElevateDB can return execution plans for any SELECT, INSERT, UPDATE, or DELETE statements. An execution plan details how ElevateDB will execute a given query, including I/O cost estimates, join re-ordering, and hints on improving execution performance. - Client Notifications
ElevateDB can send SQL execution progress, status, or log messages to the calling client application, even to remote client applications accessing an ElevateDB Server via C/S access. ElevateDB can also detect when a client application wishes to abort execution, and act accordingly.
SQL/PSM Support
ElevateDB supports a variant of the SQL-2003 SQL/PSM language for scripts, jobs, stored procedures, functions, and triggers that is geared towards dynamic SQL, and includes the following features:- Mix DDL and DML Statements
All DDL and DML statements can be mixed, and tables can be created, accessed and updated, and then dropped, all within the same SQL/PSM routine. - Dynamic Cursors and Statements
The DECLARE statement can be used to allocate cursor and statement objects that can be prepared and then opened. This allows one to prepare a specific parameterized statement once, and then execute it multiple times with parameters. Cursors are bi-directional, can be sensitive or insensitive, and can be returned as a result set cursor by stored procedures and scripts. Cursor operations supported include fetching (first, last, next, prior, relative), inserting, updating, deleting, refreshing, and retrieving the row count. - Transaction Support
Transactions can be executed within any SQL/PSM routine. - Access Multiple Databases
Access different databases from any script or job with the USE statement. - Multiple Parameter Types
Scripts, stored procedures, and functions can accept in, out, or in/out parameters. - Length-Independent VARCHAR and VARBYTE Types
VARCHAR and VARBYTE variable and parameter declarations can be made without specifying a length. - ARRAY Types
Array types are supported for any base data type, and the LENGTH and CARDINALITY functions can be used to retrieve the length of a given array. - Standard Constructs
All branching (IF and CASE) and looping (WHILE, LOOP, and REPEAT) constructs are supported. - Exception Handling
Routines can use EXCEPTION blocks that support trapping, and optionally re-raising, any exceptions. User-defined exceptions can also be raised by a routine. - Call Other Routines
Any routine can access a system or user-defined function, and can CALL other stored procedures, including recursive calls. - Advanced Triggers
Triggers can be defined as BEFORE or AFTER INSERT, UPDATE (on specific columns), DELETE, ERROR, or ALL (universal) triggers. ERROR triggers can re-raise exceptions, or raise their own exceptions. All triggers can be enabled or disabled at any time, and can access special OLDROW and NEWROW row values, including BLOBs. Triggers can also be defined to only execute when a certain condition is met. Finally, triggers can detect whether the current operation is due to the loading of replication updates, or is occurring during normal operation, along with what type of operation is currently executing (universal ALL triggers). - Client Notifications
Routines can send progress, status, or log messages to the calling client application, even to remote client applications accessing an ElevateDB Server via C/S access. Routines can also detect when a client application wishes to abort execution, and act accordingly. - Configuration and Catalog Information
The system Configuration database and database-specific Information schema tables can be accessed from any routine.
Replication
ElevateDB includes an extremely flexible replication system that consists of the following features:- All Modes Supported
Every type of replication is supported, including uni-directional, bi-directional, push, pull, merge, and snapshot (using backup/restore facilities). - Configurable Publishing
Individual tables can be configured to publish their updates, and published updates can be compressed in order to conserve space. - Incremental Hot Backup
In addition to online full backups, replication can be used to implement an incremental hot backup of any database, permitting quick switch-over to a new backup server for disaster recovery. - Virtual Store Functionality
Virtual stores are used to transfer update and backup files to and from any ElevateDB Server or installation. Stores can also be used to store any file type, thus making them useful as file repositories. Both local and remote stores can be defined, and files may be copied between any combination of store types (local to local, local to remote, etc.). Users and roles can also be assigned privileges for each defined store. - Trigger Handling
Triggers can detect when updates are being loaded for a given table, and special "on error" triggers can choose to simply log and suppress certain exceptions that may occur during the loading of the updates.
Transparent Local and Client-Server Access
Changing between local and client-server access requires a simple modification to the TYPE connection string attribute in the ODBC connection string. ElevateDB C/S access is automatically optimized for most LAN/WAN implementations, with features like:- Optimized Row Navigation
Using native ODBC function calls, you can specify the row set size that the driver uses for reading rows from an ElevateDB Server, thus allowing the developer to optimize situations where large numbers of rows are being read. - Bi-Directional Row Caching
Any rows that are read in chunks are cached client-side and can be navigated in a bi-directional manner. Also, BLOBs are always cached client-side, thus allowing for very quick C/S BLOB access.
Ordering is fast, easy, and secure, and you can be installing ElevateDB within the hour.
Order Now »
You can download a trial version of ElevateDB for Java, C/C++, or any other environment that can use ODBC for data access, and evaluate the product before your purchase.
Download Now »
Java (with Java-ODBC Bridge Driver)
C/C++ (using ODBC SDK)
Any development environment with ODBC access, such as Microsoft Visual Studio 6, Microsoft Access, Powerbuilder, and Alpha 5
C/C++ (using ODBC SDK)
Any development environment with ODBC access, such as Microsoft Visual Studio 6, Microsoft Access, Powerbuilder, and Alpha 5
This web page was last updated on Thursday, April 25, 2024 at 08:49 AM | Privacy Policy © 2024 Elevate Software, Inc. All Rights Reserved Questions or comments ? |
